食農教育融入12年國教課綱 新北完成21套教案可供課堂、戶外教學用
新北市推動食農教育融入12年國教課綱,已輔導完成21套可直接運用於課堂與戶外教學的教案,結合農業生產、飲食文化與永續理念。目前整合超過60處食農教育場域,透過實地體驗與情境學習,強化學生核心素養,打造全民參與、世代共學的食育力城市。

農業智慧化之後的挑戰-數據分析
國立臺灣大學農藝學系 劉力瑜 教授兼系主任
國立臺灣大學農藝學系生物統計與生物資訊組博士班學生 李俊翰
一、前言
隨著資訊科技軟硬體的快速發展,大數據充斥在人們的日常生活周圍,包含民生消費(便利商店)、交通(捷運公車)、防疫安全(實聯制、警消),直至每天使用的智慧型手機的資料備份等。大數據的收集與分析,近年來也應用在農業領域,從分子層級之微陣列 (microarray) 基因表現量資料、基因體或轉錄體的定序資料,到智慧農業應用於田區栽培管理的感測數據與影像資料等包羅萬象。收集數據的目的都是希望能藉由數據來轉換成有用的知識,例如透過基因表現量資料的分析瞭解基因調控機制,或者作物在不同環境下生長的速率或產量變化等。為了將數據轉換成知識,需要進行有效的數據分析。
以智慧農業為例,其中一種主要的應用方式,是結合感測設備、物聯網、大數據分析等軟硬體技術,進行作物與環境的監測,除了可以預測作物品質與產量,更希望進一步建議栽培管理行為決策。過程中收集的數據,包含大量的環境感測資訊(如:逐時的溫度、雨量、日照量等)、作物生長量化指標(如:開花日數、各器官乾物重、葉面積等)、農民或專家的栽培管理手段(如:灌溉或施肥的時機與數量、開啟溫室風扇或遮陰網等)。由於數位科技的進步,以上數據大多可自動或半自動地收集,也因此可快速累積遠比過去還要更大量的相關數據。這些數據透過系統化的收集與整合,針對不同田區規模與情境分析套用專家知識,得以進一步轉換為支援決策的資訊,因此衍生而出近年來常被提及的「專家系統」或「數位分身」等概念。從更長遠的目標來看,現代智慧農業應用更需要能及時分析環境與市場變化的相關數據,適時調整栽培管理策略。
本篇文章將以智慧農業為例,簡要介紹現行收集數據的來源或常用設備,接著簡述若干大數據常用的分析方法,最後提出農業大數據收集與分析時的幾點建議,包含實驗設計、資料視覺化與建議使用的程式語言等。
二、智慧農業數據的來源
農業數據來源,從傳統上的實驗室或田間試驗調查、感測設備(無論是否搭配物聯網傳輸)收集環境數據、到無人載具的數據或影像收集等,包羅萬象。與作物生長最密切相關的溫度與日照量等環境數據,可在田區或溫室架設微型氣象站,頻繁收集大氣相關資料,即便因成本考量無法架設私人氣象站,也可利用中央氣象局廣設的農業氣象觀測站,由中央氣象局「農業氣象觀測網監測系統」 (https://agri.coa.gov.tw) 讀取逐時氣溫、降雨量、日照輻射量、風速風向等與農業栽培應用相關的氣象資訊。過去這些氣象資訊未能即時發布,而是以旬報的方式公告,拜網路的發達,現在使用者已經可以很方便地取得最即時的訊息。另外,土壤是作物最直接取得生長所需水分及養分的媒介,因此土壤感測器也是智慧農業常使用的感測設備,很多人普遍認為監測土壤才能獲得最精確的作物水養的需求,但土壤較大氣來說均勻度不足,因此感測器取得之數據的代表性仍有待商榷。
作物生長情況、農民或專家的栽培管理手段等,過去大多透過經驗累積,少有能精確累積並傳承的數據,近年來透過影像紀錄或數位化記錄工具,例如農委會開發並推廣的「農務e把抓」等應用程式,讓數據收集更便利、更有系統,也更能透過數據單位的標準化,統整不同時間或地點的資料,使得數據得以量化並逐漸累積。無人機則是高效率收集作物生長情況的其中一種設備,可依據不同的應用目的,由無人機搭載適當規格的相機,飛到適當的高度,依適當的飛行速度在適當的間距取得影像後,搭配農業專家對影像拍攝結果的標註建立影像辨識模型,未來就能以模型的演算結果判斷作物特定的生長情況。其中無人機影像的解析度是模型能否正確判定作物生長情況的關鍵,依常理而言,飛行高度越低可取得解析度越高的影像,但由於相機拍攝角度的限制,飛行高度越低,表示取得全田區影像需要的時間越長、無人機消耗的電量越多,也表示影像檔案個數越多、未來影像分析需要的計算資源也越大。
三、數據的分析工具與實例
前述從感測器、應用程式、相機影像拍攝等各個管道,都能取得龐大數量的數據,除了挑戰資料儲存與管理的空間與效能外,接著就是如何從數據或資料中有效的萃取可實際應用於精進品種或栽培管理技術的知識。由於資料分析技術的快速發展,我們有相當多樣的分析工具,可供不同目的和形態的資料進行選擇,如熱圖(heatmap)、主成分分析(PCA)、迴歸分析(regression)等統計方法,或是支持向量機(support vector machine)、決策樹(decision tree)等機器學習方法、深度神經網路(deep neural network)等深度學習技術等,皆是在視覺化與分析農業數據上常被使用的工具。
在工具選擇上,需要考慮到分析的數據形態,以及分析的目標和運算資源來決定所使用的方法,例如機器學習和深度學習方法皆適合用於大數據建立預測模型,但兩者在計算資源需求、精確度上有所差異,需要依照分析之需求以及資源來決定要使用何種技術。舉例而言,在進行影像類資料分析時,可以使用影像特徵(feature)抽取的方式對資料進行處理,常被使用的特徵如植生指數(vegetative index, VI)、紋理特徵(texture feature)、邊緣特徵(edge feature)等。而建立辨識模型時,常用的方法則包含支持向量機(support vector machine)、決策樹(decision tree)、深度神經網路(deep neural network)等方法,使用者應該比較不同特徵及模型的特性,並建立符合需求的分析流程。
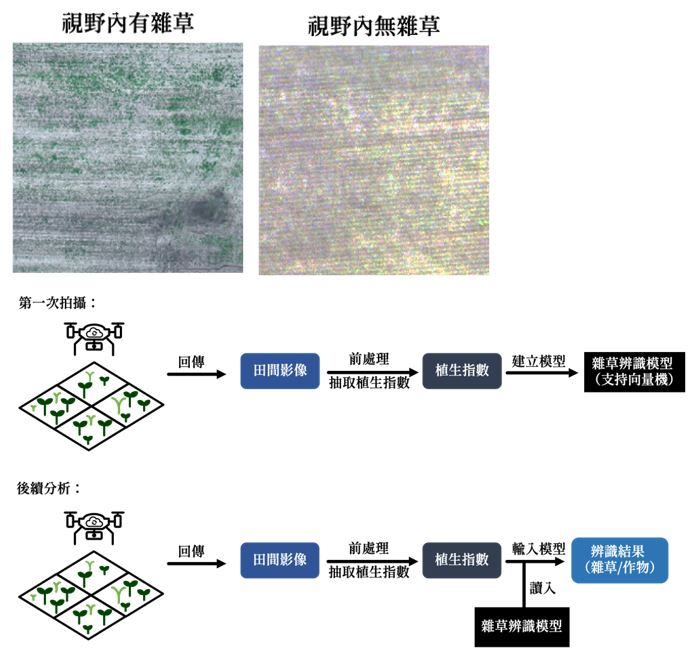
圖一、建置雜草影像辨識模型流程示意圖
不同數據來源和不同情境下的數據,在分析上方法會有很大的差異。本文以一田間雜草影像識別為例(圖一),展示農業影像分析之流程。在此雜草影像分析的辨識中,分析目標是利用無人機拍攝的全彩影像,快速的辨識拍攝的影像內有無雜草。為了達到快速辨識的目標,可將相機各個波長的反射量,轉換為植生指數以簡化資料來加快計算速度,接著以植生指數搭配影像「有無雜草」的標註結果,以支持向量機 (support vector machine) 建構影像特徵分類器模型。整體工作流程簡述如下:首先由無人機拍攝影像建立訓練資料集(包含影像及「有無雜草」的標註結果),資料回傳至主機後依序進行影像整理、抽取植生指數、以標註結果建立支持向量機模型。完成模型建置後,無人機只要進行後續影像拍攝,並對拍攝影像與訓練資料集採用相同方法抽取特徵後,將特徵輸入先前建立好的模型中,便能辨識出影像中是否有雜草。
四、展望與結語
適當的數據分析得已傳遞作物生長、環境條件等訊息,提供給使用者判斷結果並做出適當的決策,前提是「收集的數據」與「決策的目標」具有關聯性,也因此,試驗前的實驗設計會是資料能否獲得適切分析結果的關鍵。實驗設計包含選擇適當的觀測變數、決定觀測數據的數量或各個處理的重複數量、判斷是否需要設置區集 (block) 以控制實驗現場影響試驗數據變動的因子等,透過事先規劃取得數據的方式與流程,能更確實掌握數據的穩定性及可分析性,比起事後才來決定分析的統計方法,更能避免錯付時間與成本。
如同前一節所述,在統計分析方法的選擇上,需考慮數據形態及運算資源。其中,數據形態可透過適當的圖形呈現、將數據視覺化,有助使用者更了解數據的特性,例如數據是否有未知的分組情況?是否有不正常的極端值出現?是否有過度集中的不均衡數據導致部分因子被過度強調其重要性?等,避免未經去除雜訊的數據做出不穩定的分析結果,或套用不適當甚至錯誤的統計或機器學習模式導致錯誤決策。
隨著數據大量累積,無論是數據視覺化或建立分類預測等統計模型,均需要搭配程式語言來進行,以資料科學應用的領域來說,目前普遍使用的R與Python兩種語言,對於初學者的進入門檻也都比過去常用的其他語言低,且也都有可免費下載之軟體供使用者操作。網路上不時可見哪一種語言使用率較高的爭論,但依據筆者的經驗,無論選擇哪一種程式語言,只要多加練習,將該語言的分析繪圖等應用做到精熟,使能確實掌握數據分析的正確性,均能達到最終決策的目的。

國立臺灣大學農藝學系